Мы с важной новостью: с 28 февраля 2025 года сервис Хабр Фриланс прекратит свою работу.
Купить услуги можно до 28 февраля 2025, но пополнить баланс уже нельзя. Если на вашем счете остались средства, вы можете потратить их на небольшие услуги — служба поддержки готова поделиться бонусами, на случай, если средств немного не хватает.

IT Разработчик
Парсер веб - страниц
Добавлено
10 окт 2021 в 13:46
Вот моя небольшая работа.
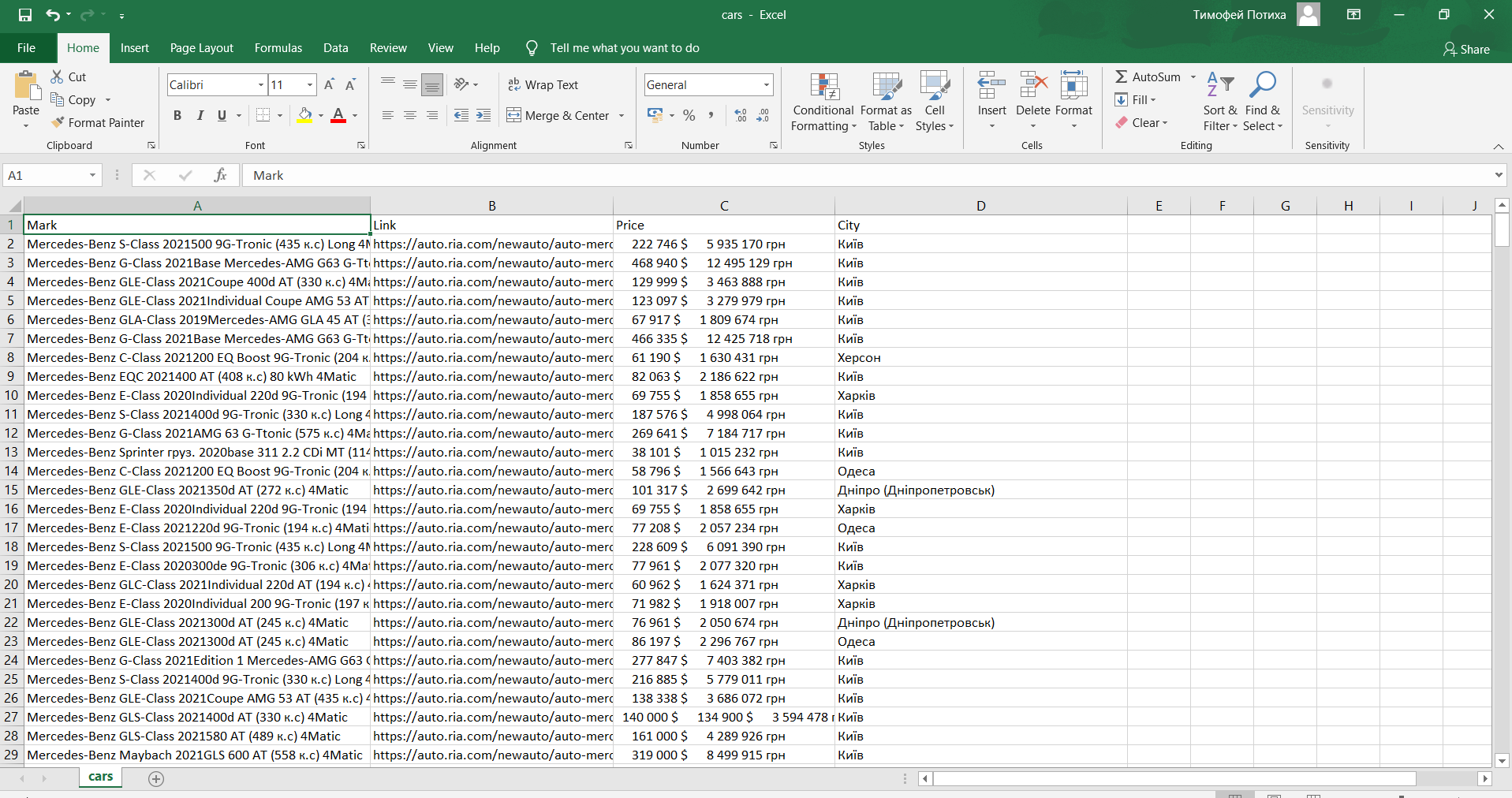
Парсер веб сайта - https://auto.ria.com/uk/newauto/marka-mercedes-ben...
Написан он был на Python.
Код проекта :
import requests
from bs4 import BeautifulSoup
import csv
URL = 'https://auto.ria.com/uk/newauto/marka-mercedes-...'
HEADERS = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36'}
HOST = 'https://auto.ria.com'
FILE='cars.csv'
def save_file(items,path):
with open(path,'w',newline='')as file:
writer= csv.writer(file,delimiter=';')
writer.writerow(['Mark','Link','Price','City'])
for item in items:
writer.writerow([item['tilte'],item['link'],item['price'],item['city']])
def get_pages_count(html):
soup = BeautifulSoup(html, 'html.parser')
pagination = soup.find_all('span',class_='mhide')
if pagination:
return int (pagination [-1].get_text())
else:
return 1
print(pagination)
def get_html(url,params=None):
r=requests.get(url,headers =HEADERS,params=params)
return r
def get_content(html):
soup = BeautifulSoup( html,'html.parser')
items = soup.find_all('section', class_='proposition')
cars=[]
for item in items:
cars.append({
'tilte': item.find('div',class_='proposition_title').get_text(strip=True),
'link': HOST+item.find('a', class_='proposition_link').get('href'),
'price': item.find('div',class_='proposition_price').get_text().replace('•',''),
'city': item.find('span',class_='item region').get_text()
})
return cars
def parse():
html=get_html(URL)
if html.status_code==200:
cars =[]
pages_count=get_pages_count(html.text)
for page in range(1,pages_count):
print(f'Парсинг страницы{page} из {pages_count}...')
html=get_html(URL,params={'page':page})
cars.extend(get_content(html.text))
save_file(cars,FILE)
print(f'Получено {len(cars)} атомобилей ')
parse()
Парсер веб сайта - https://auto.ria.com/uk/newauto/marka-mercedes-ben...
Написан он был на Python.
Код проекта :
import requests
from bs4 import BeautifulSoup
import csv
URL = 'https://auto.ria.com/uk/newauto/marka-mercedes-...'
HEADERS = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36'}
HOST = 'https://auto.ria.com'
FILE='cars.csv'
def save_file(items,path):
with open(path,'w',newline='')as file:
writer= csv.writer(file,delimiter=';')
writer.writerow(['Mark','Link','Price','City'])
for item in items:
writer.writerow([item['tilte'],item['link'],item['price'],item['city']])
def get_pages_count(html):
soup = BeautifulSoup(html, 'html.parser')
pagination = soup.find_all('span',class_='mhide')
if pagination:
return int (pagination [-1].get_text())
else:
return 1
print(pagination)
def get_html(url,params=None):
r=requests.get(url,headers =HEADERS,params=params)
return r
def get_content(html):
soup = BeautifulSoup( html,'html.parser')
items = soup.find_all('section', class_='proposition')
cars=[]
for item in items:
cars.append({
'tilte': item.find('div',class_='proposition_title').get_text(strip=True),
'link': HOST+item.find('a', class_='proposition_link').get('href'),
'price': item.find('div',class_='proposition_price').get_text().replace('•',''),
'city': item.find('span',class_='item region').get_text()
})
return cars
def parse():
html=get_html(URL)
if html.status_code==200:
cars =[]
pages_count=get_pages_count(html.text)
for page in range(1,pages_count):
print(f'Парсинг страницы{page} из {pages_count}...')
html=get_html(URL,params={'page':page})
cars.extend(get_content(html.text))
save_file(cars,FILE)
print(f'Получено {len(cars)} атомобилей ')
parse()