Мы с важной новостью: с 28 февраля 2025 года сервис Хабр Фриланс прекратит свою работу.
Купить услуги можно до 28 февраля 2025, но пополнить баланс уже нельзя. Если на вашем счете остались средства, вы можете потратить их на небольшие услуги — служба поддержки готова поделиться бонусами, на случай, если средств немного не хватает.

Python-Developer
Парсинг веб-приложения "Beli"
Добавлено
22 ноя 2022 в 19:19
Ссылка на GitHub: scraping_app.beliapp.com
Цель
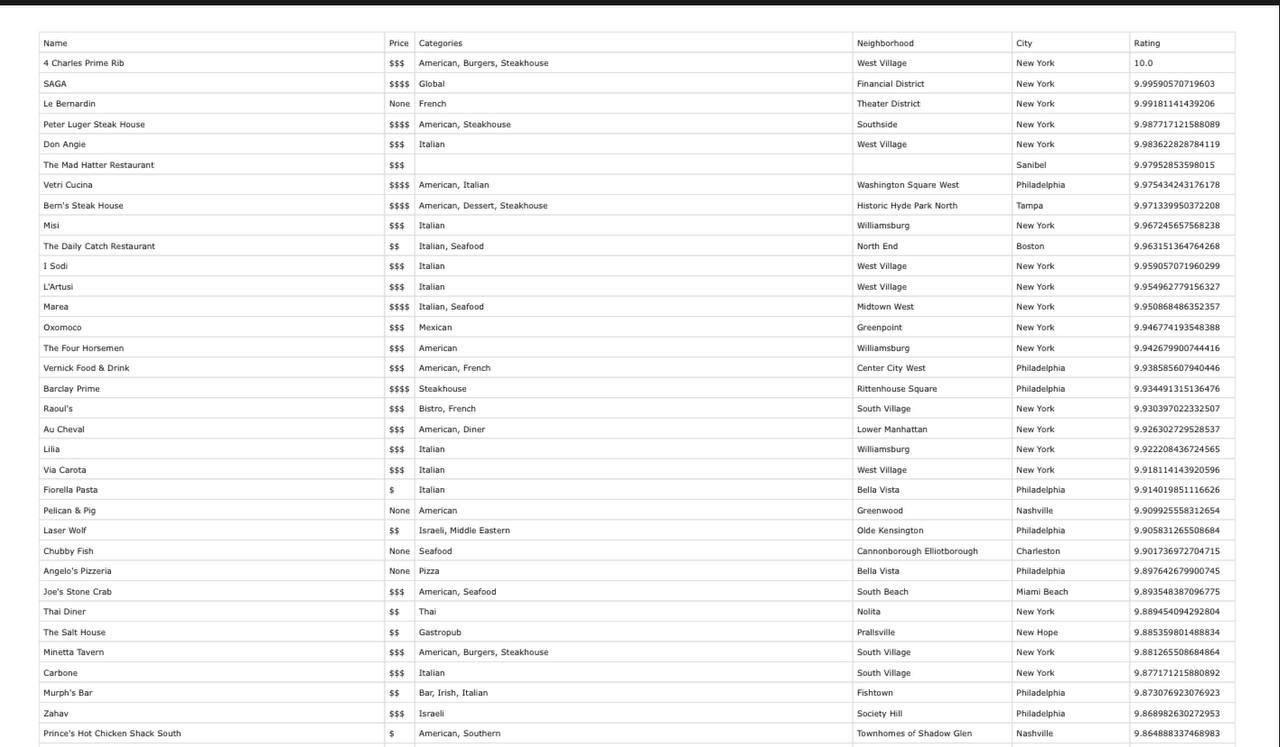
Заказчик хотел собрать данные о ресторанах из веб-приложения «Beli». Нужно было собрать все данные обо всех ресторанах из списка ресторанов в веб-приложении и записать данные в csv файл
Решение
Парсинг любого сайта начинается с анализа и планирования работы. Первый шаг — просмотреть сайт, чтобы понять, с чем нам приходится иметь дело.
Веб-приложение очень простое. Он состоит из списка карточек ресторанов и малоинтересной для нас рекламной кнопки «Скачать Beli». Когда страница загружается, у нас есть список из 20 карточек ресторанов. Однако при прокрутке списка новые карточки загружаются автоматически, без нажатия кнопок и перехода на другие страницы. Это означает, что новые карты загружаются с использованием Java Script.
Скорее всего на сайте есть API, через который Java Script подгружает нужные данные. Таким образом, у нас есть два варианта развития события:
1. Пробуем делать запросы к API. Если API открыто для внешних запросов, мы получаем всю информацию из API и записываем ее в файл csv в нужном формате
2. Если API не принимает внешние запросы, используем инструмент Selenium, благодаря которому мы будем нажимать на карточки ресторанов, чтобы страница прокручивалась вниз и Java Script загружал нам новые карточки ресторанов, пока мы не получим их все
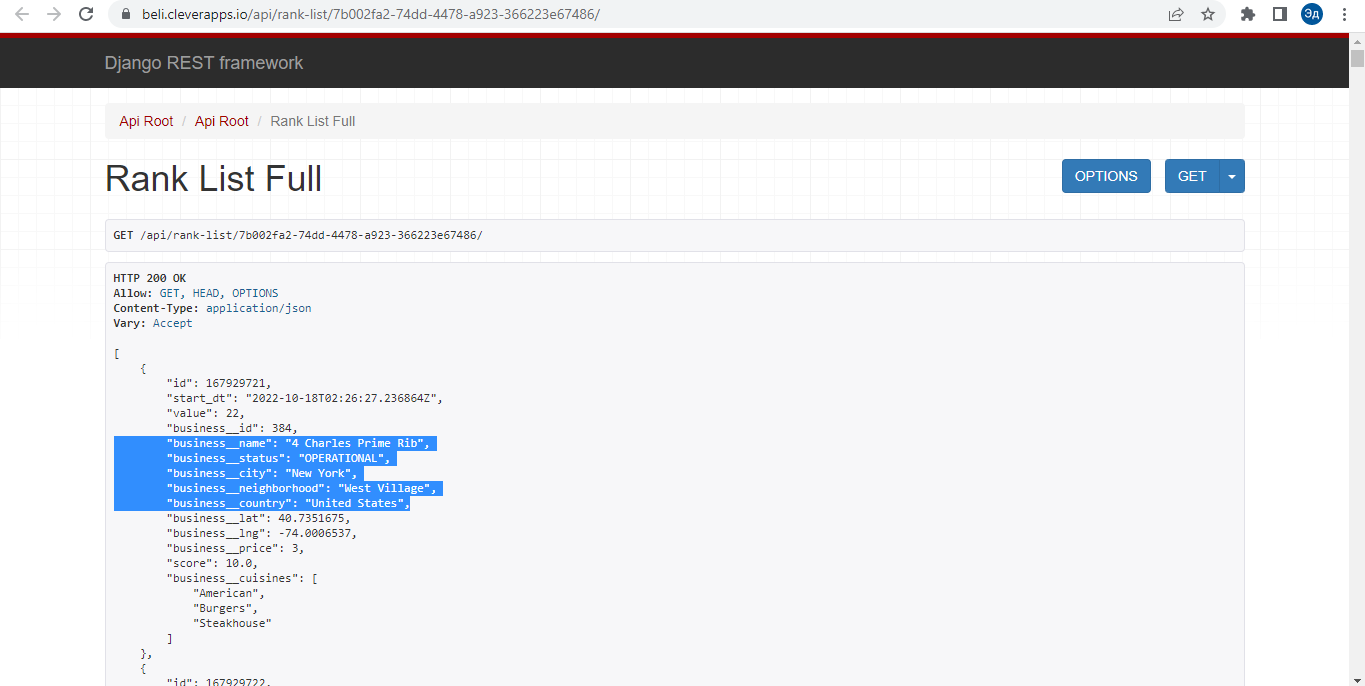
Сначала попробуем проверить первый способ, так как он более предпочтителен из-за своей простоты и быстрого действия. При попытке решить проблему первым способом мы видим, что на сайте действительно есть API, благодаря которому осуществляется загрузка данных. Более того, этот API открыт для внешних Get-запросов, то есть мы можем легко получить всю необходимую нам информацию очень простым способом. Нам просто нужно записать данные в файл csv
Цель
Заказчик хотел собрать данные о ресторанах из веб-приложения «Beli». Нужно было собрать все данные обо всех ресторанах из списка ресторанов в веб-приложении и записать данные в csv файл
Решение
Парсинг любого сайта начинается с анализа и планирования работы. Первый шаг — просмотреть сайт, чтобы понять, с чем нам приходится иметь дело.
Веб-приложение очень простое. Он состоит из списка карточек ресторанов и малоинтересной для нас рекламной кнопки «Скачать Beli». Когда страница загружается, у нас есть список из 20 карточек ресторанов. Однако при прокрутке списка новые карточки загружаются автоматически, без нажатия кнопок и перехода на другие страницы. Это означает, что новые карты загружаются с использованием Java Script.
Скорее всего на сайте есть API, через который Java Script подгружает нужные данные. Таким образом, у нас есть два варианта развития события:
1. Пробуем делать запросы к API. Если API открыто для внешних запросов, мы получаем всю информацию из API и записываем ее в файл csv в нужном формате
2. Если API не принимает внешние запросы, используем инструмент Selenium, благодаря которому мы будем нажимать на карточки ресторанов, чтобы страница прокручивалась вниз и Java Script загружал нам новые карточки ресторанов, пока мы не получим их все
Сначала попробуем проверить первый способ, так как он более предпочтителен из-за своей простоты и быстрого действия. При попытке решить проблему первым способом мы видим, что на сайте действительно есть API, благодаря которому осуществляется загрузка данных. Более того, этот API открыт для внешних Get-запросов, то есть мы можем легко получить всю необходимую нам информацию очень простым способом. Нам просто нужно записать данные в файл csv