Мы с важной новостью: с 28 февраля 2025 года сервис Хабр Фриланс прекратит свою работу.
Купить услуги можно до 28 февраля 2025, но пополнить баланс уже нельзя. Если на вашем счете остались средства, вы можете потратить их на небольшие услуги — служба поддержки готова поделиться бонусами, на случай, если средств немного не хватает.
Универсальный копировщик
Добавлено
18 окт 2017 в 14:57
Для работы внешних нормативных БД используется специально разработанная единая структура БД.
Данные же от поставщиков приходят в самых разных форматах: Paradox, DBase, Access, XML, структурированный текст. Структура этих данных тоже, естественно, у каждого поставщика может быть своя.
Требуется все это скопировать в БД нашей структуры.
Т.е. по идее, требуется целое семейство программ-копировщиков. В нашем случае задача была решена написанием одной программы.
Основой программы служит базовый класс копировщика - DataCopier.
Он умеет проанализировать каталог с исходными данными, создать новую БД, получить данные от прикрепленного к нему источника данных, скопировать БД, сделать ее архив.
Источники данных - потомки класса DataSourceReader - умеют прочитать исходные данные и представить их в виде таблиц. Т.е. на каждый формат исходных данных используется свой подкласс источника данных.
Каждый копировщик задает свои алгоритмы - какие таблицы надо копировать, и как это делать, перекрывая виртуальные методы CopyDataBase и т.п.
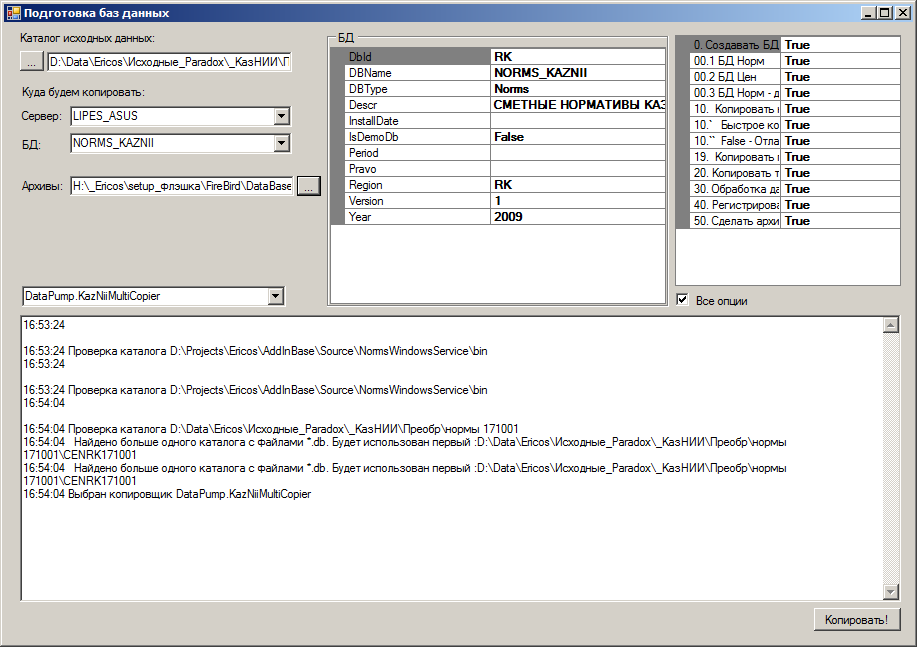
На форме мы задаем основные параметры - местонахождение сервера, каталог архивов БД и, самое главное - каталог с исходными данными.
Форма через механизм Reflection находит определенные в программе классы копировщиков (т.е. при появлении новых классов копировщиков эту процедуру менять не надо), каждому из них дает каталог на проверку - может ли он скопировать эти данные.
(Каждый копировщик имеет виртуальный метод CheckDirectory, определяющий, находятся ли в указанном каталоге подходящие ему данные.)
Первый копировщик, признавший данные в исходном каталоге, выбирается для работы. Таким образом, программа при указании каталога исходных данных автоматически определяет подходящий копировщик. Если автоматическое определение сделано ошибочно - пользователь может указать нужный копировщик вручную.
При нажатии кнопки Копировать программа создает новую БД, копирует в нее данные, после чего делает архив БД (средствами сервера БД), который уже передается пользователю для установки.
В ходе копирования программа ведет лог (протокол) работы, отмечая, какие таблицы скопированы, сколько записей было обработано, сколько времени на это ушло, какие в ходе работы возникли ошибки или особые ситуации. Таким образом, пользователь видит, что программа делает, а также может проанализировать ход работы задним числом - например, чтоб поправить исходные данные, либо сообщить программисту о возникших проблемах.
При появлении новых исходных данных программист разрабатывает новый подкласс копировщика, определяя в нем алгоритм копирования и алгоритм распознавания "своих" исходных данных. Далее, как мы видели, программа уже сама разберется, что с ним делать и когда его запускать.
Типичное время копирования БД - от 1 до 5 часов, в зависимости от структуры и объема данных.
Данные же от поставщиков приходят в самых разных форматах: Paradox, DBase, Access, XML, структурированный текст. Структура этих данных тоже, естественно, у каждого поставщика может быть своя.
Требуется все это скопировать в БД нашей структуры.
Т.е. по идее, требуется целое семейство программ-копировщиков. В нашем случае задача была решена написанием одной программы.
Основой программы служит базовый класс копировщика - DataCopier.
Он умеет проанализировать каталог с исходными данными, создать новую БД, получить данные от прикрепленного к нему источника данных, скопировать БД, сделать ее архив.
Источники данных - потомки класса DataSourceReader - умеют прочитать исходные данные и представить их в виде таблиц. Т.е. на каждый формат исходных данных используется свой подкласс источника данных.
Каждый копировщик задает свои алгоритмы - какие таблицы надо копировать, и как это делать, перекрывая виртуальные методы CopyDataBase и т.п.
На форме мы задаем основные параметры - местонахождение сервера, каталог архивов БД и, самое главное - каталог с исходными данными.
Форма через механизм Reflection находит определенные в программе классы копировщиков (т.е. при появлении новых классов копировщиков эту процедуру менять не надо), каждому из них дает каталог на проверку - может ли он скопировать эти данные.
(Каждый копировщик имеет виртуальный метод CheckDirectory, определяющий, находятся ли в указанном каталоге подходящие ему данные.)
Первый копировщик, признавший данные в исходном каталоге, выбирается для работы. Таким образом, программа при указании каталога исходных данных автоматически определяет подходящий копировщик. Если автоматическое определение сделано ошибочно - пользователь может указать нужный копировщик вручную.
При нажатии кнопки Копировать программа создает новую БД, копирует в нее данные, после чего делает архив БД (средствами сервера БД), который уже передается пользователю для установки.
В ходе копирования программа ведет лог (протокол) работы, отмечая, какие таблицы скопированы, сколько записей было обработано, сколько времени на это ушло, какие в ходе работы возникли ошибки или особые ситуации. Таким образом, пользователь видит, что программа делает, а также может проанализировать ход работы задним числом - например, чтоб поправить исходные данные, либо сообщить программисту о возникших проблемах.
При появлении новых исходных данных программист разрабатывает новый подкласс копировщика, определяя в нем алгоритм копирования и алгоритм распознавания "своих" исходных данных. Далее, как мы видели, программа уже сама разберется, что с ним делать и когда его запускать.
Типичное время копирования БД - от 1 до 5 часов, в зависимости от структуры и объема данных.