Мы с важной новостью: с 28 февраля 2025 года сервис Хабр Фриланс прекратит свою работу.
Купить услуги можно до 28 февраля 2025, но пополнить баланс уже нельзя. Если на вашем счете остались средства, вы можете потратить их на небольшие услуги — служба поддержки готова поделиться бонусами, на случай, если средств немного не хватает.

Python-Developer
Парсинг государственного сайта Oklahoma Medical Marijuana Authority
Добавлено
11 ноя 2022 в 04:38
Ссылка на GitHub: scraping_omma.us.thentiacloud.net
Цель
Заказчик хотел собрать данные о диспансерах с сайта.
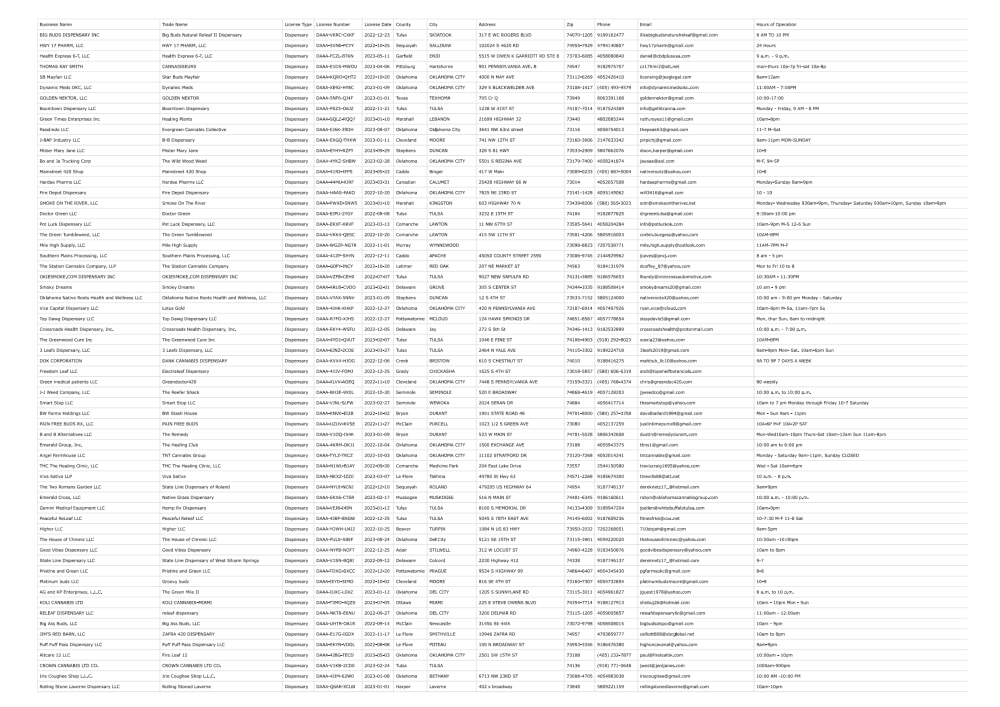
Необходимо было собрать данные (фирменное наименование, торговое наименование, тип лицензии, номер лицензии, дата лицензии, округ, город, адрес, почтовый индекс, телефон, почта, время работы) по всем диспансерам на сайте и записать их в файл csv
Решение
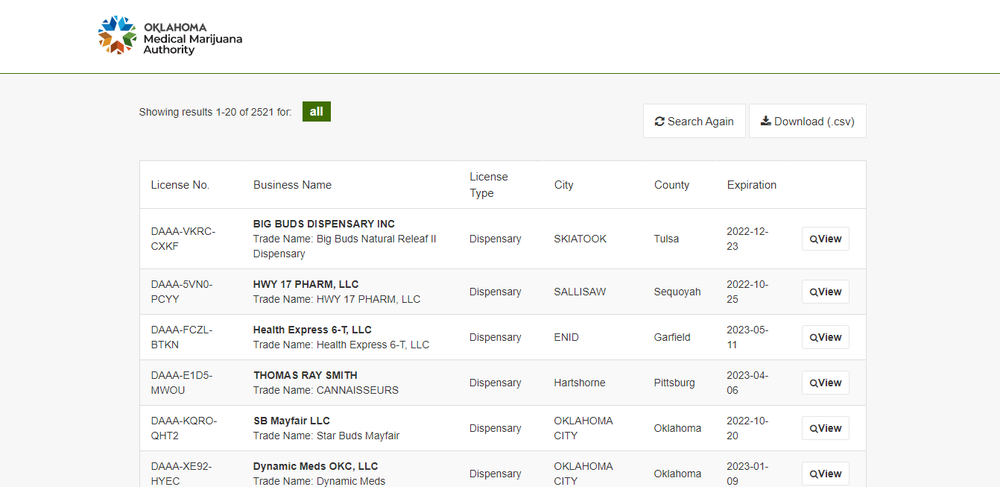
Парсинг любого сайта начинается с анализа и планирования выполнения работ. Первый шаг — просмотреть сайт, чтобы понять, с чем нам предстоит иметь дело.
На сайте есть удобная кнопка "Скачать (.csv)". Однако, если бы все было так просто, этого заказа не существовало бы. И было бы странно показывать в своем портфолио, как я умею нажимать кнопку =) Дело в том, что при нажатии на кнопку "Скачать (.csv)" скачивается файл csv, в котором содержится неполная информация, необходимая заказчику . Поэтому продолжаем анализировать сайт
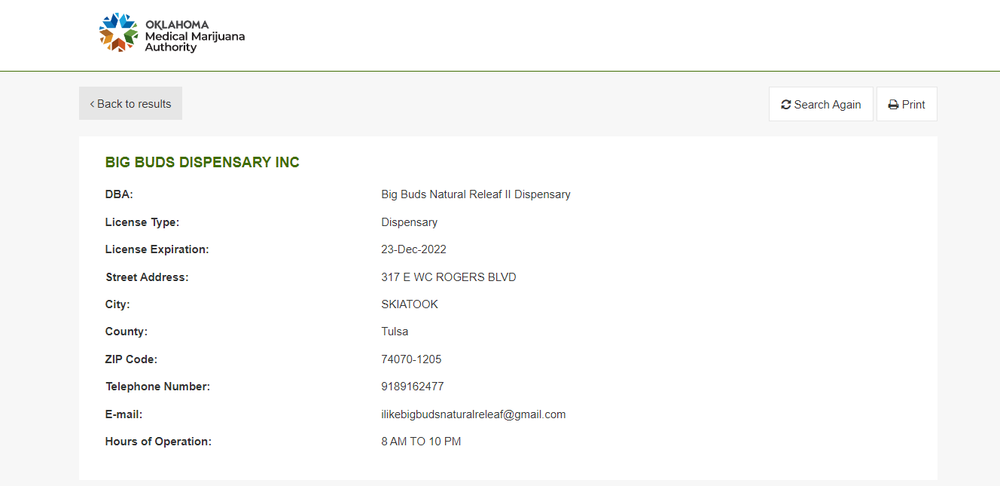
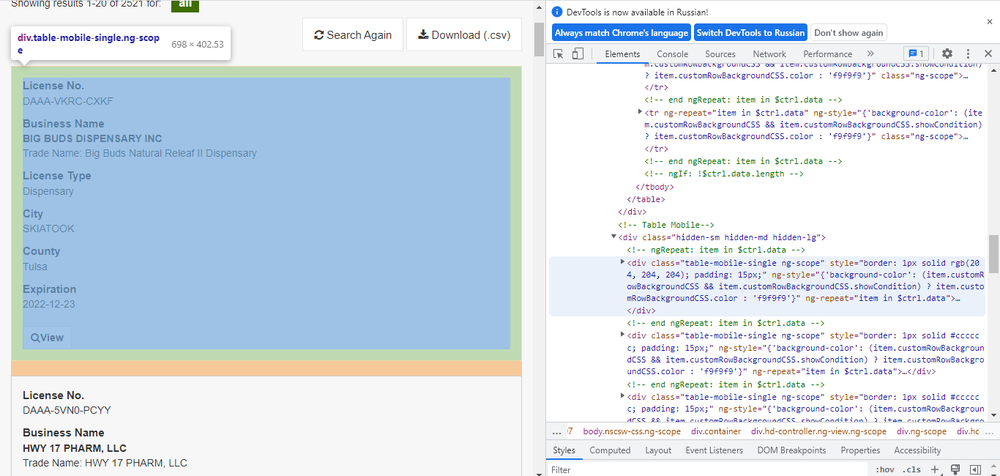
Сайт имеет простую структуру HTML с кнопками для навигации и переключения между страницами. Интересующие нас данные находятся в тегах div с классом table-mobile-single ng-scope, откуда мы можем получить часть необходимой нам информации. Чтобы получить остальные данные, нам нужно нажать на кнопку «просмотреть». Нам также нужно использовать кнопку «Следующая страница» для перехода между страницами.
Когда мы нажимаем на кнопки «Просмотр» и «Следующая страница», страница сайта не перезагружается, то есть данные загружаются с помощью Java Script. Таким образом, у нас есть два пути решения задачи:
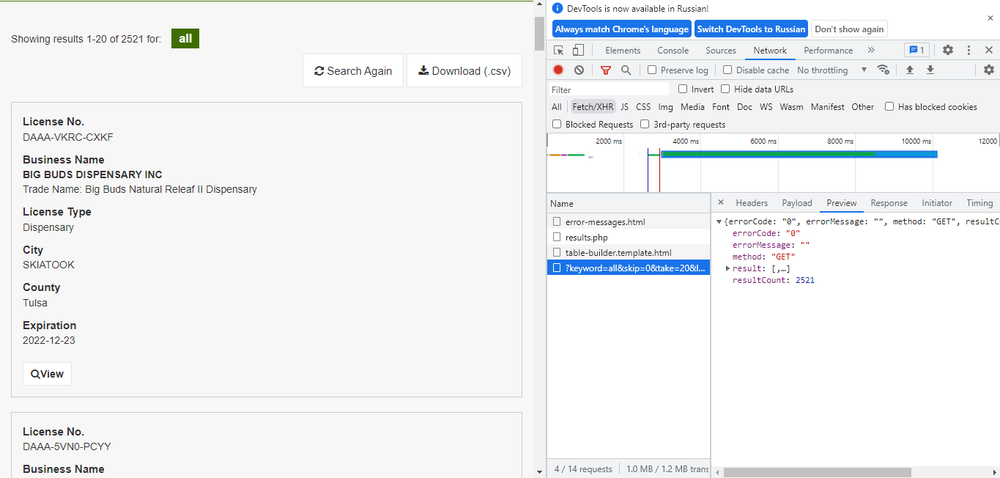
1. Попробуем найти API, через который сайт загружает данные с помощью Java Script. Сделаем необходимые запросы к API. Если API открыт для внешних запросов, мы получаем информацию через API. Это очень простой и быстрый способ парсинга данных, но он не всегда работает, так как все зависит от настроек и безопасности сервера, который отправляет данные.
2. Используем библиотеки Selenium и BeautifulSoup. Через Selenium мы будем запускать Java Script, нажимая кнопки. BeautifulSoup поможет нам собрать данные, загруженные с помощью Java Script. Это более сложный и длительный способ, но более надежный, так как таким образом мы точно сможем собрать все необходимые данные.
При проверке первого способа через API мы видим, что на сайте открытое API, которое принимает запросы на получение и отправляет данные в формате json. Эти данные содержат всю необходимую нам информацию. То есть второй способ становится для нас неинтересным, так как все необходимые данные мы получили через более быстрый и простой способ. Осталось только извлечь данные из json и записать в правильном формате csv
Цель
Заказчик хотел собрать данные о диспансерах с сайта.
Необходимо было собрать данные (фирменное наименование, торговое наименование, тип лицензии, номер лицензии, дата лицензии, округ, город, адрес, почтовый индекс, телефон, почта, время работы) по всем диспансерам на сайте и записать их в файл csv
Решение
Парсинг любого сайта начинается с анализа и планирования выполнения работ. Первый шаг — просмотреть сайт, чтобы понять, с чем нам предстоит иметь дело.
На сайте есть удобная кнопка "Скачать (.csv)". Однако, если бы все было так просто, этого заказа не существовало бы. И было бы странно показывать в своем портфолио, как я умею нажимать кнопку =) Дело в том, что при нажатии на кнопку "Скачать (.csv)" скачивается файл csv, в котором содержится неполная информация, необходимая заказчику . Поэтому продолжаем анализировать сайт
Сайт имеет простую структуру HTML с кнопками для навигации и переключения между страницами. Интересующие нас данные находятся в тегах div с классом table-mobile-single ng-scope, откуда мы можем получить часть необходимой нам информации. Чтобы получить остальные данные, нам нужно нажать на кнопку «просмотреть». Нам также нужно использовать кнопку «Следующая страница» для перехода между страницами.
Когда мы нажимаем на кнопки «Просмотр» и «Следующая страница», страница сайта не перезагружается, то есть данные загружаются с помощью Java Script. Таким образом, у нас есть два пути решения задачи:
1. Попробуем найти API, через который сайт загружает данные с помощью Java Script. Сделаем необходимые запросы к API. Если API открыт для внешних запросов, мы получаем информацию через API. Это очень простой и быстрый способ парсинга данных, но он не всегда работает, так как все зависит от настроек и безопасности сервера, который отправляет данные.
2. Используем библиотеки Selenium и BeautifulSoup. Через Selenium мы будем запускать Java Script, нажимая кнопки. BeautifulSoup поможет нам собрать данные, загруженные с помощью Java Script. Это более сложный и длительный способ, но более надежный, так как таким образом мы точно сможем собрать все необходимые данные.
При проверке первого способа через API мы видим, что на сайте открытое API, которое принимает запросы на получение и отправляет данные в формате json. Эти данные содержат всю необходимую нам информацию. То есть второй способ становится для нас неинтересным, так как все необходимые данные мы получили через более быстрый и простой способ. Осталось только извлечь данные из json и записать в правильном формате csv