Мы с важной новостью: с 28 февраля 2025 года сервис Хабр Фриланс прекратит свою работу.
Купить услуги можно до 28 февраля 2025, но пополнить баланс уже нельзя. Если на вашем счете остались средства, вы можете потратить их на небольшие услуги — служба поддержки готова поделиться бонусами, на случай, если средств немного не хватает.

Python-Developer
Парсинг сайта статей "Hattiesburg American"
Добавлено
11 ноя 2022 в 05:00
Ссылка на GitHub: scraping_hattiesburgamerican.com
Цель
Заказчик хотел собрать данные о статьях с сайта
Необходимо было собрать данные (Текст, URL) по всем статьям на сайте и записать их в сsv файл
Решение
Парсинг любого сайта начинается с анализа и планирования работы. Первый шаг — просмотреть сайт, чтобы понять, с чем нам приходится иметь дело.
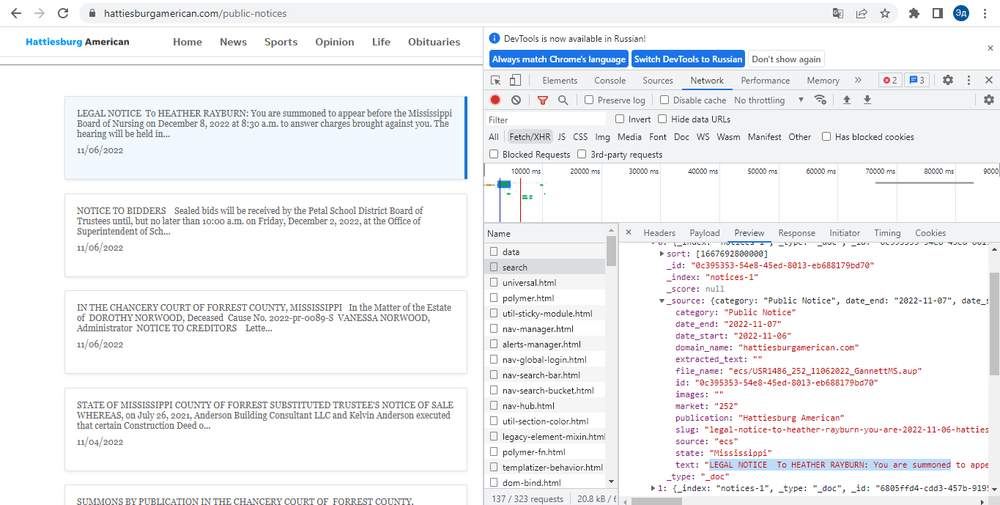
На сайте есть кнопки навигации по страницам и блоки статей, при нажатии на которые загружается полный текст статьи и дополнительная информация о статье. При нажатии на кнопку "Следующая страница" или на блок статьи страница сайта не перезагружается. Таким образом, мы можем сделать вывод, что переход между страницами и полная информация о статье загружаются с помощью Java Script.
Наши следующие шаги:
1. Попробуем найти API, через который сайт загружает данные с помощью Java Script. Сделаем необходимые запросы API. Если API открыт для внешних запросов, мы получаем информацию через API. Это очень простой и быстрый способ парсинга данных, но он не всегда работает, так как все зависит от настроек и безопасности сервера, который отправляет данные.
2. Используйте библиотеки Selenium и BeautifulSoup. Через Selenium мы будем запускать Java Script по нажатию кнопки. BeautifulSoup поможет нам собрать данные, загруженные с помощью Java Script. Это более сложный и длительный способ, но более надежный, так как таким образом мы точно сможем собрать все необходимые данные.
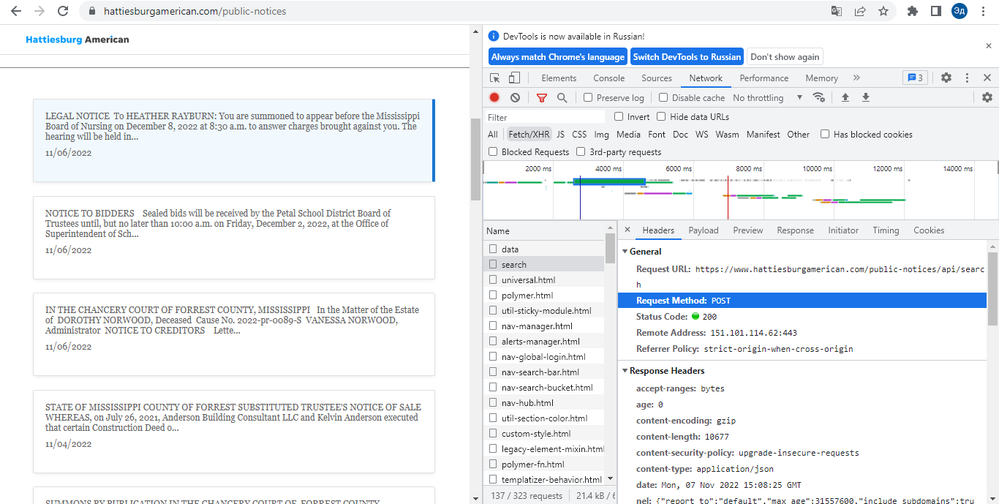
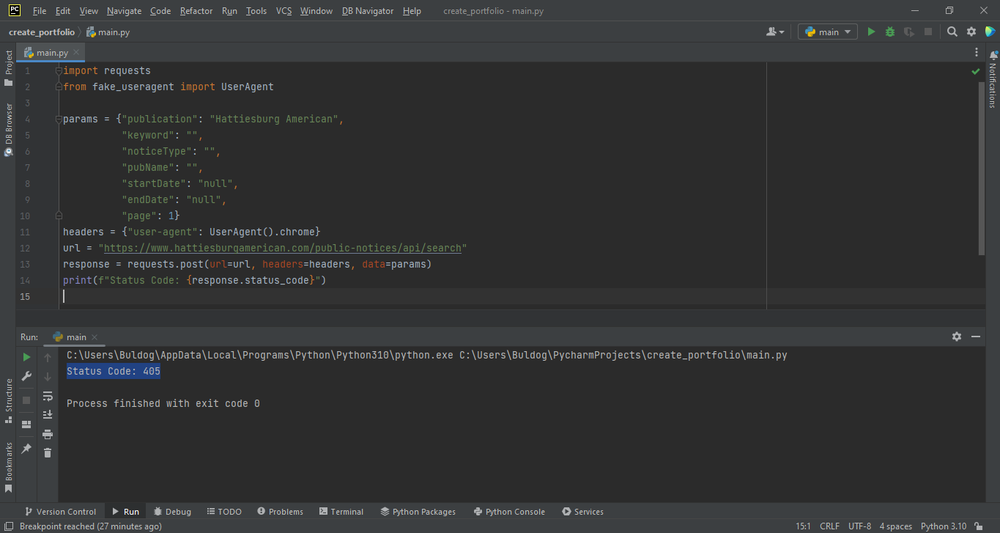
При проверке первого метода через API мы видим, что при отправке get-запроса мы получаем HTTP ERROR 405. Это вовсе не означает, что API закрыто для внешних запросов. Дело в том, что сайт сам отправляет запрос в формате post-запроса с дополнительными параметрами, которые мы можем найти во вкладке Payload. При попытке отправить post-запрос с нужными параметрами мы все равно получаем ту же HTTP ERROR 405. То есть API по-прежнему закрыт для внешних запросов. То есть нам нужно использовать второй способ.
Суть второго способа заключается в том, чтобы нажать на статью, получить данные о статье, затем нажать на следующую статью и так далее, пока не дойдем до конца страницы. Далее необходимо нажать на кнопку «Следующая страница» и далее повторять все действия до тех пор, пока мы не обойдем все страницы на сайте. При получении данных о каждой статье мы сразу записываем их в файл с расширением .csv
С точки зрения написания кода программа не сложная. Однако на обработку всего сайта потребуется больше времени, чем на получение данных через API
Цель
Заказчик хотел собрать данные о статьях с сайта
Необходимо было собрать данные (Текст, URL) по всем статьям на сайте и записать их в сsv файл
Решение
Парсинг любого сайта начинается с анализа и планирования работы. Первый шаг — просмотреть сайт, чтобы понять, с чем нам приходится иметь дело.
На сайте есть кнопки навигации по страницам и блоки статей, при нажатии на которые загружается полный текст статьи и дополнительная информация о статье. При нажатии на кнопку "Следующая страница" или на блок статьи страница сайта не перезагружается. Таким образом, мы можем сделать вывод, что переход между страницами и полная информация о статье загружаются с помощью Java Script.
Наши следующие шаги:
1. Попробуем найти API, через который сайт загружает данные с помощью Java Script. Сделаем необходимые запросы API. Если API открыт для внешних запросов, мы получаем информацию через API. Это очень простой и быстрый способ парсинга данных, но он не всегда работает, так как все зависит от настроек и безопасности сервера, который отправляет данные.
2. Используйте библиотеки Selenium и BeautifulSoup. Через Selenium мы будем запускать Java Script по нажатию кнопки. BeautifulSoup поможет нам собрать данные, загруженные с помощью Java Script. Это более сложный и длительный способ, но более надежный, так как таким образом мы точно сможем собрать все необходимые данные.
При проверке первого метода через API мы видим, что при отправке get-запроса мы получаем HTTP ERROR 405. Это вовсе не означает, что API закрыто для внешних запросов. Дело в том, что сайт сам отправляет запрос в формате post-запроса с дополнительными параметрами, которые мы можем найти во вкладке Payload. При попытке отправить post-запрос с нужными параметрами мы все равно получаем ту же HTTP ERROR 405. То есть API по-прежнему закрыт для внешних запросов. То есть нам нужно использовать второй способ.
Суть второго способа заключается в том, чтобы нажать на статью, получить данные о статье, затем нажать на следующую статью и так далее, пока не дойдем до конца страницы. Далее необходимо нажать на кнопку «Следующая страница» и далее повторять все действия до тех пор, пока мы не обойдем все страницы на сайте. При получении данных о каждой статье мы сразу записываем их в файл с расширением .csv
С точки зрения написания кода программа не сложная. Однако на обработку всего сайта потребуется больше времени, чем на получение данных через API