Мы с важной новостью: с 28 февраля 2025 года сервис Хабр Фриланс прекратит свою работу.
Купить услуги можно до 28 февраля 2025, но пополнить баланс уже нельзя. Если на вашем счете остались средства, вы можете потратить их на небольшие услуги — служба поддержки готова поделиться бонусами, на случай, если средств немного не хватает.

Python-Developer
Парсинг международного онлайн-магазина электронных сим-карт "Airalo"
Добавлено
11 ноя 2022 в 05:20
Ссылка на GitHub: scraping_airalo.com
Цель
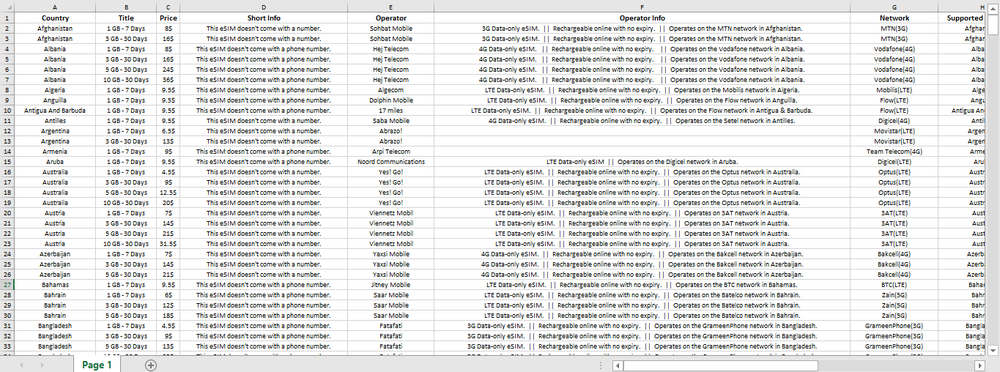
Клиент хотел собрать данные об электронных SIM-картах с сайта. Необходимо было собрать данные (Страна, Название, Цена, Краткая информация, Оператор, Информация об операторе, Сеть, Поддерживаемые страны, Дополнительная информация) по всем e-SIM на сайте и записать их в файл xlsx
Решение
Парсинг любого сайта начинается с анализа и планирования работы. Первый шаг — просмотреть сайт, чтобы понять, с чем нам приходится иметь дело.
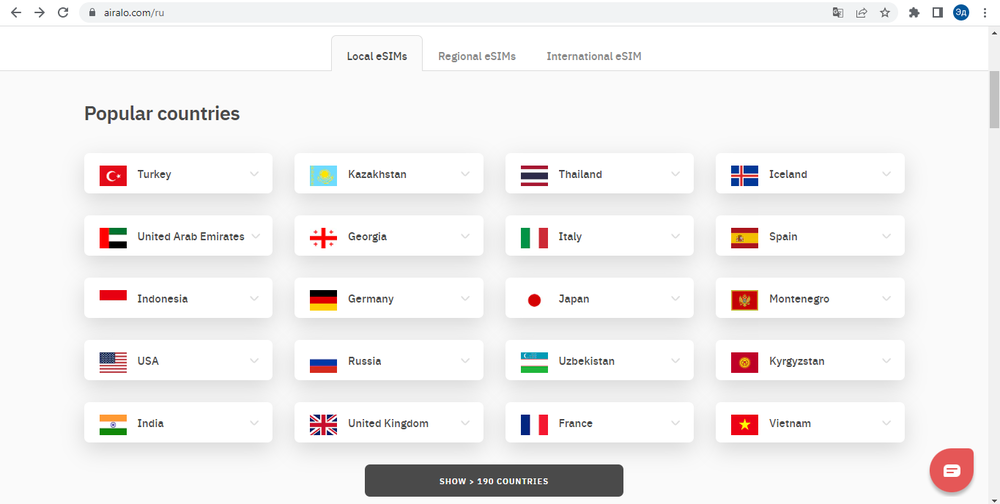
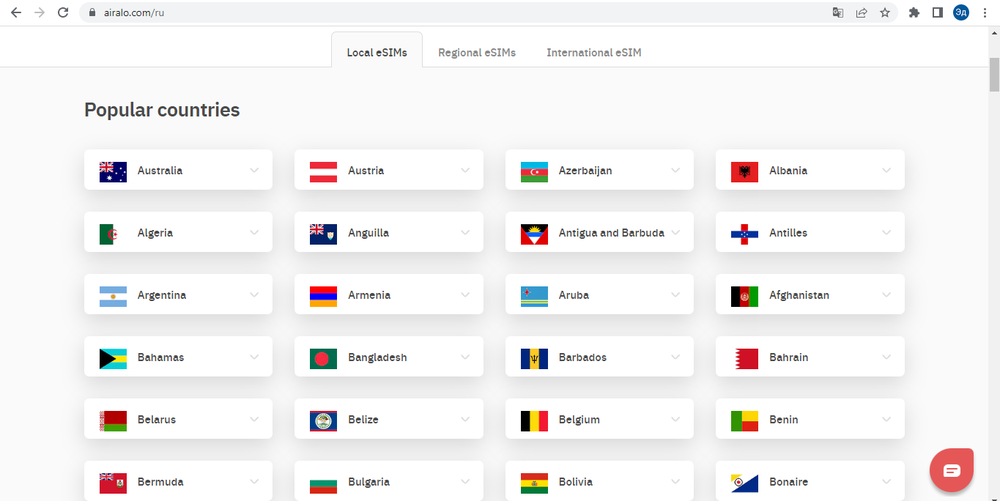
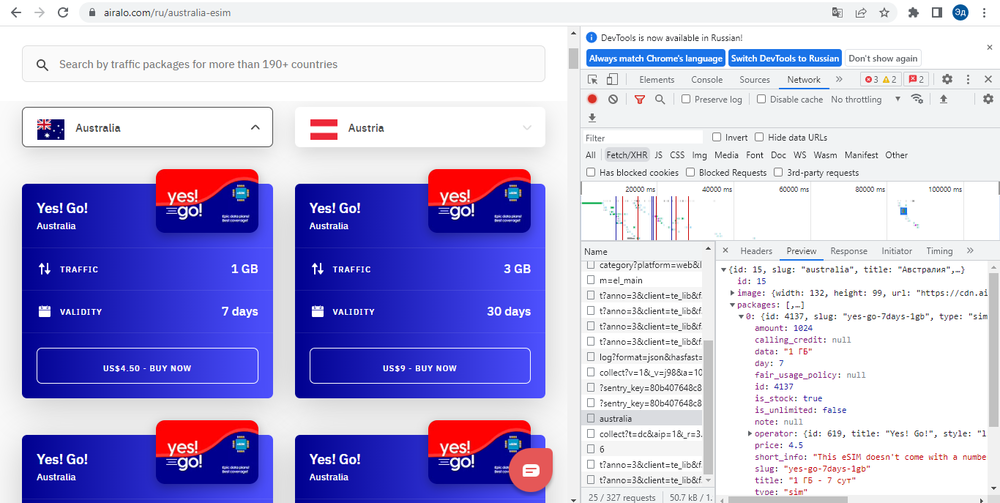
На сайте простой интерфейс выбора страны и кнопка «Все страны» внизу. При нажатии на кнопку «Все страны» открывается полный список стран. Когда вы нажимаете на блок страны, открывается список доступных электронных SIM-карт в этой стране.
На первый взгляд из-за дизайна сайта можно подумать, что при нажатии на кнопки срабатывает Java Script, который загружает все необходимые данные. Однако, если мы посмотрим на URL-адрес при нажатии на блоки, мы увидим, что сайт загружает другую страницу. То есть кнопки не вызывают Java Script, а просто перенаправляют нас на другую страницу сайта
Таким образом, мы понимаем, что при выполнении работы мы можем ограничиться библиотеками "requests" и "BeautifulSoup"
У нас есть два способа получить данные с сайта:
1. Попробуем найти доступ к API сайта. А если API принимает внешние запросы, получим необходимую информацию через API
2. Напрямую делать запросы к страницам сайта, соответствующим каждой стране, и собрать с них информацию с помощью библиотеки BeautifulSoup
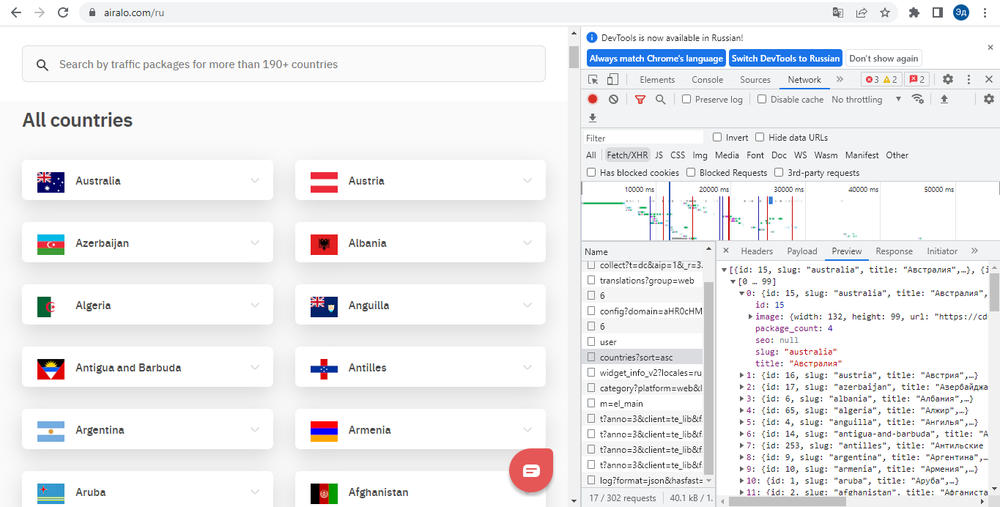
Для начала попробуем проверить первый способ, так как работать через API всегда быстрее и проще. Если проанализировать вкладку «сеть», то мы можем увидеть два интересующих нас запроса: загрузка списка стран, загрузка информации о e-Sims по нажатию на блок страны
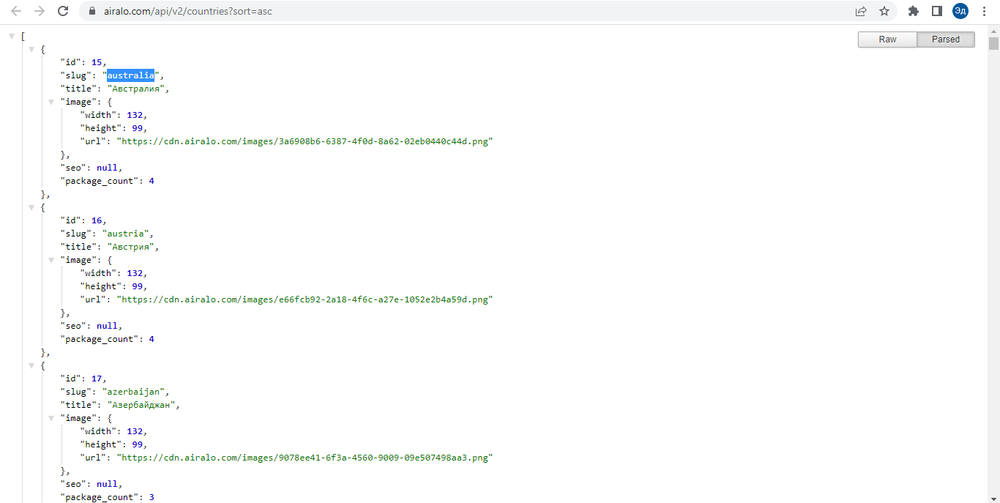
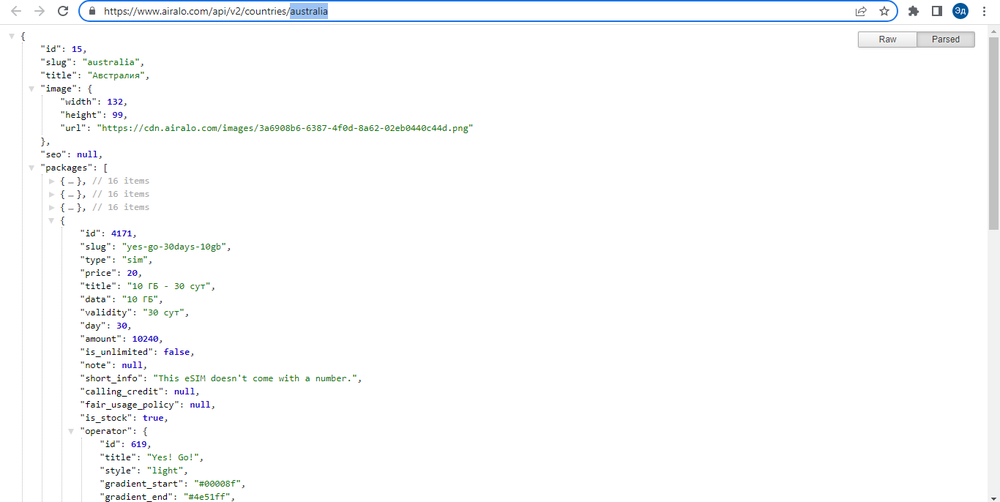
1. Запрос, из которого загружается список стран, содержит полную информацию о странах в формате JSON и доступен через браузер (т. е. поддерживает классический GET-запрос)
2. Запрос с информацией о e-SIM также содержит полную информацию обо всех доступных e-SIM в определенной стране в формате JSON и также доступен через классический GET-запрос.
В первом запросе единственным нужным полем будет поле «slug», из которого мы возьмем строковое представление страны в пути запроса. Со второго запроса мы собираем всю необходимую информацию об e-SIM.
Таким образом, алгоритм работы следующий:
1. Получить значение поля «slug» в первом запросе
2. Подставляем это значение в путь второго запроса
3. Собираем нужную информацию со второго запроса
4. Записываем полученные данные в файл xlsx
5. Повторяем алгоритм, пока не обойдем все поля "slug" первого запроса
Цель
Клиент хотел собрать данные об электронных SIM-картах с сайта. Необходимо было собрать данные (Страна, Название, Цена, Краткая информация, Оператор, Информация об операторе, Сеть, Поддерживаемые страны, Дополнительная информация) по всем e-SIM на сайте и записать их в файл xlsx
Решение
Парсинг любого сайта начинается с анализа и планирования работы. Первый шаг — просмотреть сайт, чтобы понять, с чем нам приходится иметь дело.
На сайте простой интерфейс выбора страны и кнопка «Все страны» внизу. При нажатии на кнопку «Все страны» открывается полный список стран. Когда вы нажимаете на блок страны, открывается список доступных электронных SIM-карт в этой стране.
На первый взгляд из-за дизайна сайта можно подумать, что при нажатии на кнопки срабатывает Java Script, который загружает все необходимые данные. Однако, если мы посмотрим на URL-адрес при нажатии на блоки, мы увидим, что сайт загружает другую страницу. То есть кнопки не вызывают Java Script, а просто перенаправляют нас на другую страницу сайта
Таким образом, мы понимаем, что при выполнении работы мы можем ограничиться библиотеками "requests" и "BeautifulSoup"
У нас есть два способа получить данные с сайта:
1. Попробуем найти доступ к API сайта. А если API принимает внешние запросы, получим необходимую информацию через API
2. Напрямую делать запросы к страницам сайта, соответствующим каждой стране, и собрать с них информацию с помощью библиотеки BeautifulSoup
Для начала попробуем проверить первый способ, так как работать через API всегда быстрее и проще. Если проанализировать вкладку «сеть», то мы можем увидеть два интересующих нас запроса: загрузка списка стран, загрузка информации о e-Sims по нажатию на блок страны
1. Запрос, из которого загружается список стран, содержит полную информацию о странах в формате JSON и доступен через браузер (т. е. поддерживает классический GET-запрос)
2. Запрос с информацией о e-SIM также содержит полную информацию обо всех доступных e-SIM в определенной стране в формате JSON и также доступен через классический GET-запрос.
В первом запросе единственным нужным полем будет поле «slug», из которого мы возьмем строковое представление страны в пути запроса. Со второго запроса мы собираем всю необходимую информацию об e-SIM.
Таким образом, алгоритм работы следующий:
1. Получить значение поля «slug» в первом запросе
2. Подставляем это значение в путь второго запроса
3. Собираем нужную информацию со второго запроса
4. Записываем полученные данные в файл xlsx
5. Повторяем алгоритм, пока не обойдем все поля "slug" первого запроса