Мы с важной новостью: с 28 февраля 2025 года сервис Хабр Фриланс прекратит свою работу.
Купить услуги можно до 28 февраля 2025, но пополнить баланс уже нельзя. Если на вашем счете остались средства, вы можете потратить их на небольшие услуги — служба поддержки готова поделиться бонусами, на случай, если средств немного не хватает.

Python-Developer
Парсинг сайта недвижимости в Америке «Realtor.com»
Добавлено
22 ноя 2022 в 19:11
Ссылка на GitHub: scraping_realtor.com
Цель
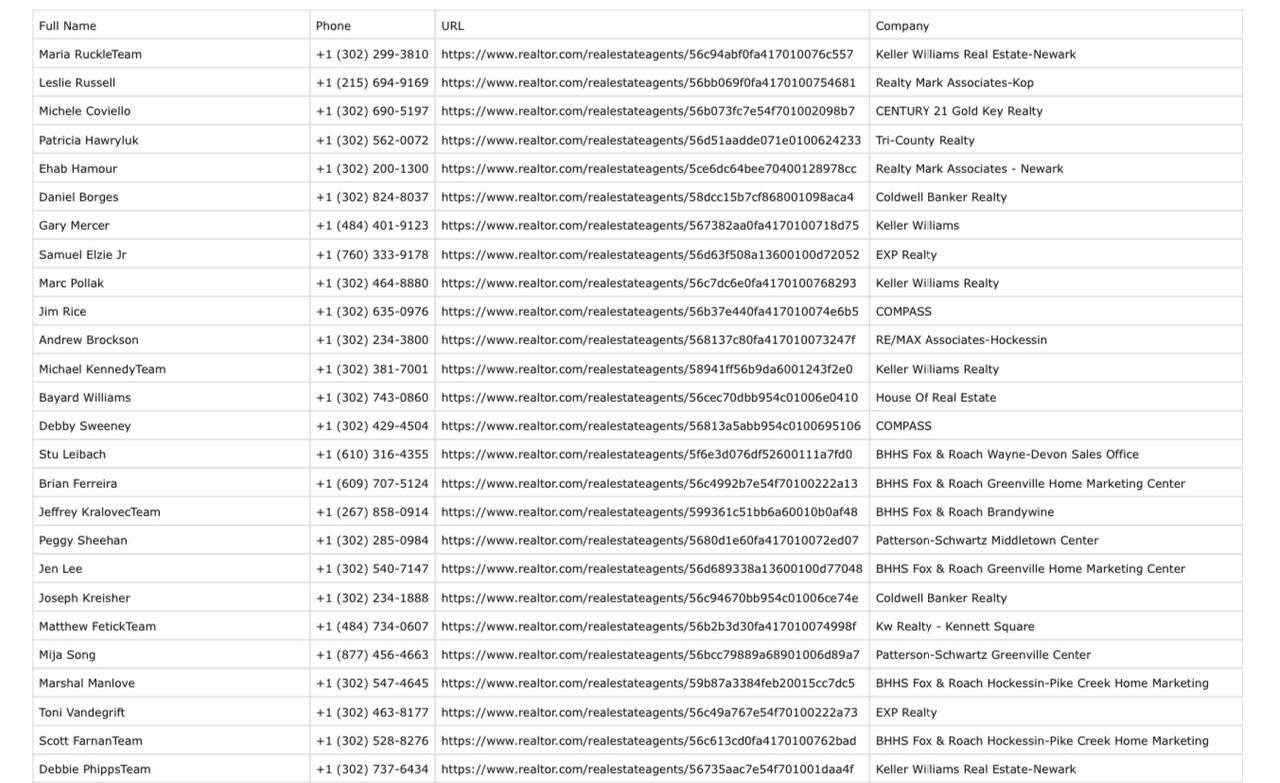
Заказчик хотел собрать данные о риелторах с сайта. Нужно было собрать данные (Имя, Телефон, URL, Компания) обо всех риелторах из штата Делавэр на сайте и записать данные в csv файл.
Решение
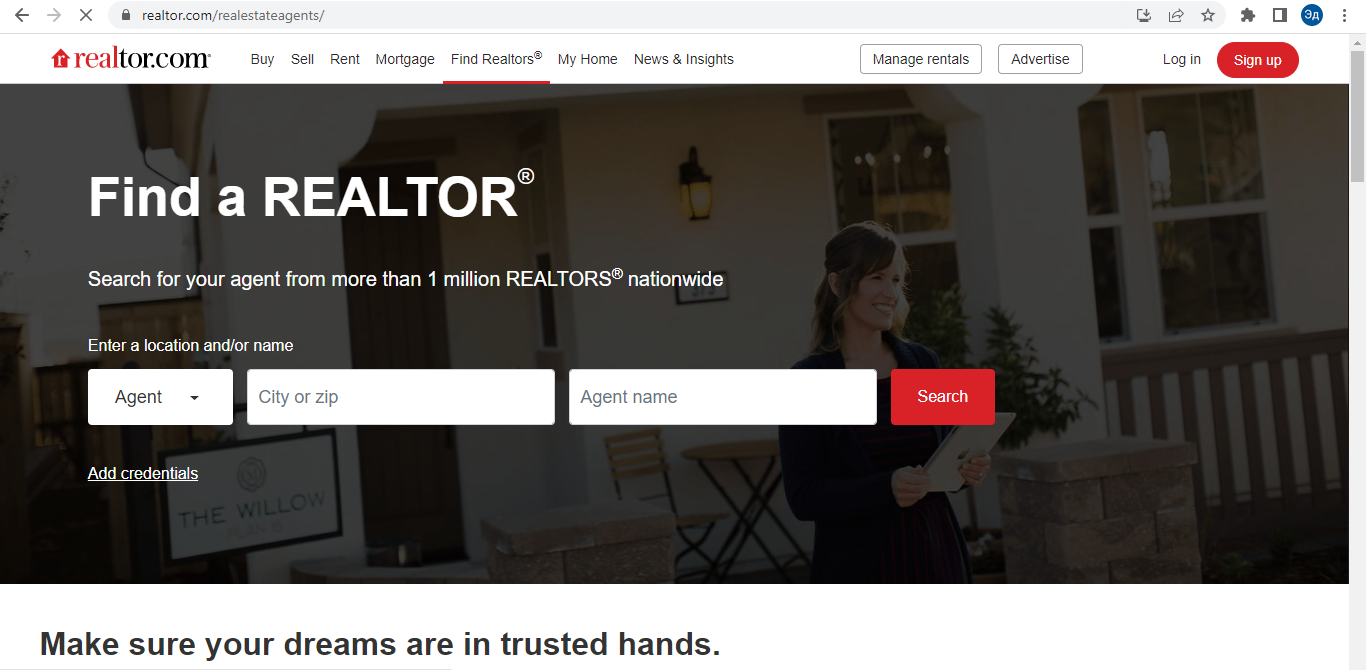
Парсинг любого сайта начинается с анализа и планирования работы. Первый шаг — просмотреть сайт, чтобы понять, с чем нам приходится иметь дело.
На сайте есть классическая панель навигации вверху, где мы можем выбрать раздел «Риэлторы». Поиск риелторов осуществляется по фильтрам «Местоположение» и «Имя». Здесь мы сталкиваемся с небольшим осложнением. Дело в том, что сайт ищет только города. То есть мы не сможем выбрать все государство в одном поисковом запросе. При попытке выполнить поиск по штату Делавэр без указания штата сайт возвращает результаты для города Делавэр, штат Огайо. То есть искать придется по каждому отдельному городу штата.
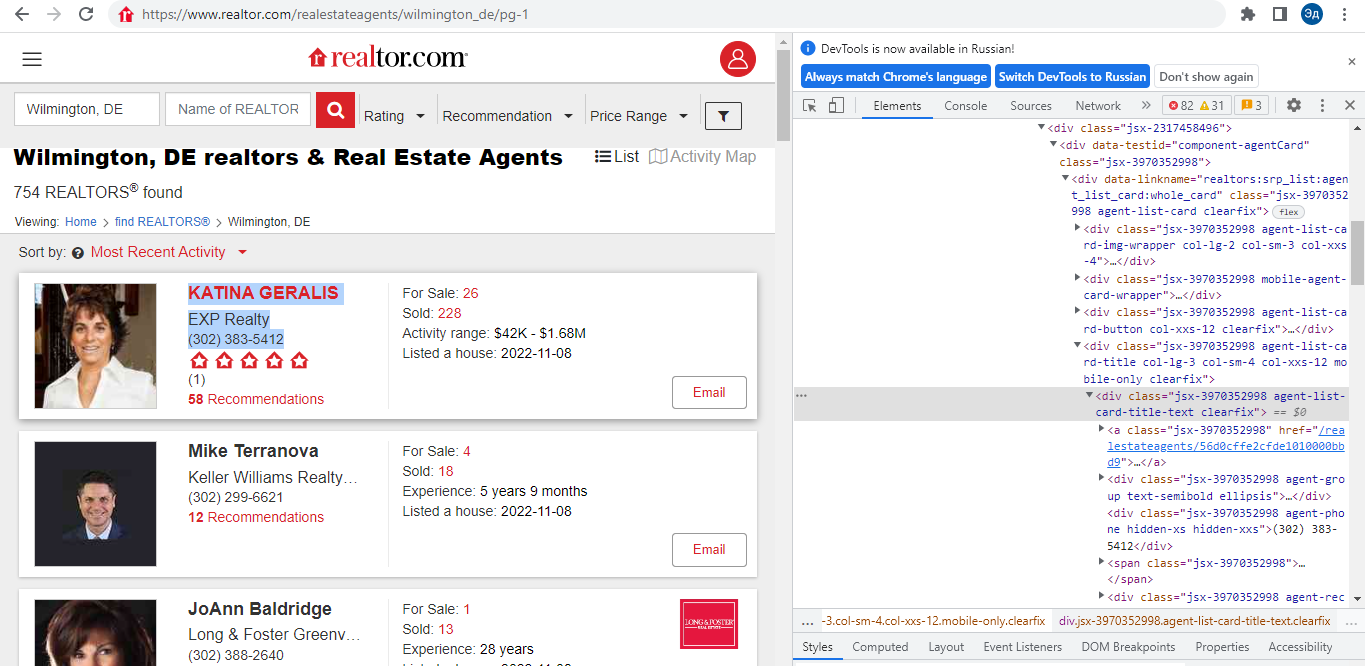
Мы можем решить эту проблему с помощью Selenium, каждый раз заполняя форму поиска нужными значениями. Однако в данном случае я бы не стал использовать Selenium, так как Selenium медленнее, чем классические Get-запросы. Вместо этого мы можем проверить URL-адрес сайта при выполнении поискового запроса. Дело в том, что с каждым поисковым запросом URL сайта меняется. Это означает, что поисковый запрос не использует Java Script для загрузки данных, а просто загружает новую страницу сайта. То есть без Selenium в данном случае можно обойтись. Нам достаточно подставить в URL название города заглавными буквами и первые две буквы в названии штата в формате {название города}_{первые две буквы в названии штата}, и мы получим желаемый поисковый запрос
Страница, которая является результатом поискового запроса, представляет собой список карточек риелтора и панель навигации по страницам. Навигация также осуществляется с помощью ссылок на другие страницы сайта. Поэтому мы можем использовать запросы Get для навигации между страницами. Каждый поисковый запрос имеет разное количество возвращаемых результатов и разное количество страниц. К счастью для нас, панель навигации предоставляет нам не только кнопки «Следующая страница» и «Предыдущая страница», но также первую и последнюю страницы поискового запроса. То есть мы можем взять количество страниц в поисковом запросе с первой страницы.
В заключение стоит отметить, что для получения риелторских данных по всему штату Делавэр нам необходимо прокрутить все города штата и собрать информацию из них. Но не забывайте, что данные риелторов могут дублироваться в двух и более городах. Поэтому при сборе данных нам необходимо выполнить дублирующую проверку. Это можно сделать с помощью уникального идентификатора, например URL-адреса риелтора. И только в том случае, когда URL риелтора ранее не встречался, вносим данные в файл
Осталось только собрать необходимые данные через BeautifulSoup и поместить их в csv файл
Цель
Заказчик хотел собрать данные о риелторах с сайта. Нужно было собрать данные (Имя, Телефон, URL, Компания) обо всех риелторах из штата Делавэр на сайте и записать данные в csv файл.
Решение
Парсинг любого сайта начинается с анализа и планирования работы. Первый шаг — просмотреть сайт, чтобы понять, с чем нам приходится иметь дело.
На сайте есть классическая панель навигации вверху, где мы можем выбрать раздел «Риэлторы». Поиск риелторов осуществляется по фильтрам «Местоположение» и «Имя». Здесь мы сталкиваемся с небольшим осложнением. Дело в том, что сайт ищет только города. То есть мы не сможем выбрать все государство в одном поисковом запросе. При попытке выполнить поиск по штату Делавэр без указания штата сайт возвращает результаты для города Делавэр, штат Огайо. То есть искать придется по каждому отдельному городу штата.
Мы можем решить эту проблему с помощью Selenium, каждый раз заполняя форму поиска нужными значениями. Однако в данном случае я бы не стал использовать Selenium, так как Selenium медленнее, чем классические Get-запросы. Вместо этого мы можем проверить URL-адрес сайта при выполнении поискового запроса. Дело в том, что с каждым поисковым запросом URL сайта меняется. Это означает, что поисковый запрос не использует Java Script для загрузки данных, а просто загружает новую страницу сайта. То есть без Selenium в данном случае можно обойтись. Нам достаточно подставить в URL название города заглавными буквами и первые две буквы в названии штата в формате {название города}_{первые две буквы в названии штата}, и мы получим желаемый поисковый запрос
Страница, которая является результатом поискового запроса, представляет собой список карточек риелтора и панель навигации по страницам. Навигация также осуществляется с помощью ссылок на другие страницы сайта. Поэтому мы можем использовать запросы Get для навигации между страницами. Каждый поисковый запрос имеет разное количество возвращаемых результатов и разное количество страниц. К счастью для нас, панель навигации предоставляет нам не только кнопки «Следующая страница» и «Предыдущая страница», но также первую и последнюю страницы поискового запроса. То есть мы можем взять количество страниц в поисковом запросе с первой страницы.
В заключение стоит отметить, что для получения риелторских данных по всему штату Делавэр нам необходимо прокрутить все города штата и собрать информацию из них. Но не забывайте, что данные риелторов могут дублироваться в двух и более городах. Поэтому при сборе данных нам необходимо выполнить дублирующую проверку. Это можно сделать с помощью уникального идентификатора, например URL-адреса риелтора. И только в том случае, когда URL риелтора ранее не встречался, вносим данные в файл
Осталось только собрать необходимые данные через BeautifulSoup и поместить их в csv файл