Мы с важной новостью: с 28 февраля 2025 года сервис Хабр Фриланс прекратит свою работу.
Купить услуги можно до 28 февраля 2025, но пополнить баланс уже нельзя. Если на вашем счете остались средства, вы можете потратить их на небольшие услуги — служба поддержки готова поделиться бонусами, на случай, если средств немного не хватает.

Python-Developer
Парсинг онлайн-галереи сайтов "Awwwards"
Добавлено
22 ноя 2022 в 20:27
Ссылка на GitHub: scraping_awwwards
Цель
Заказчик хотел собрать данные о сайтах онлайн-галереи Awwwards. Нужно было собрать все адреса сайтов из каталога онлайн галереи и записать их в txt файл
Решение
Парсинг любого сайта начинается с анализа и планирования работы. Первый шаг — просмотреть сайт, чтобы понять, с чем нам приходится иметь дело.
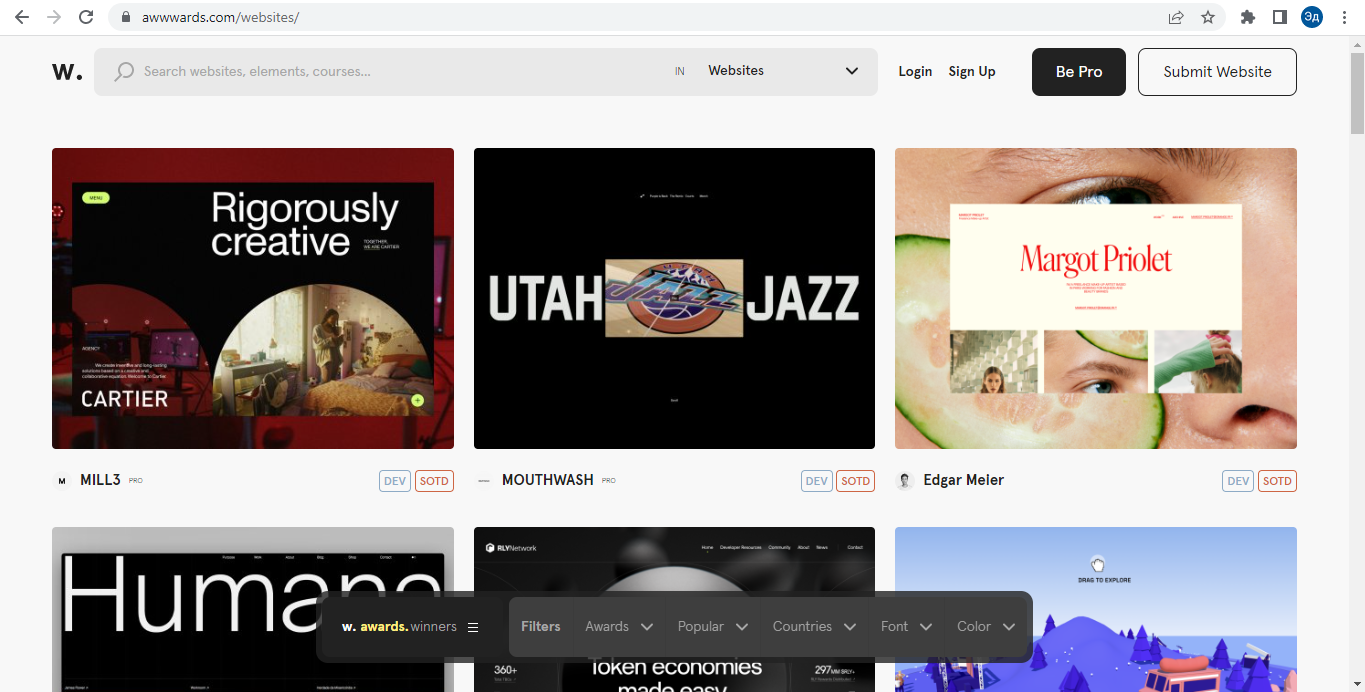
Сайт имеет стандартную структуру карточек сайтов, панель фильтрации поиска и панель навигации по страницам. Нас интересуют карточки сайтов и панель навигации по страницам, так как нам не нужны никакие критерии фильтрации.
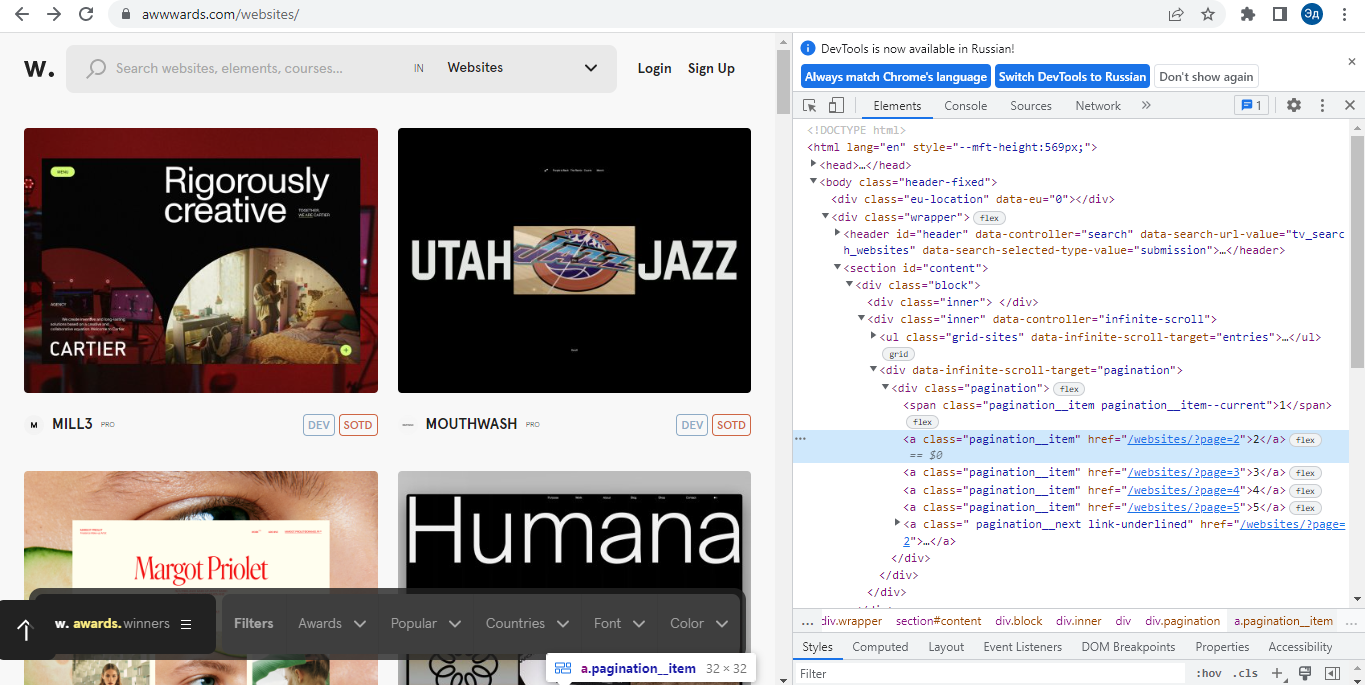
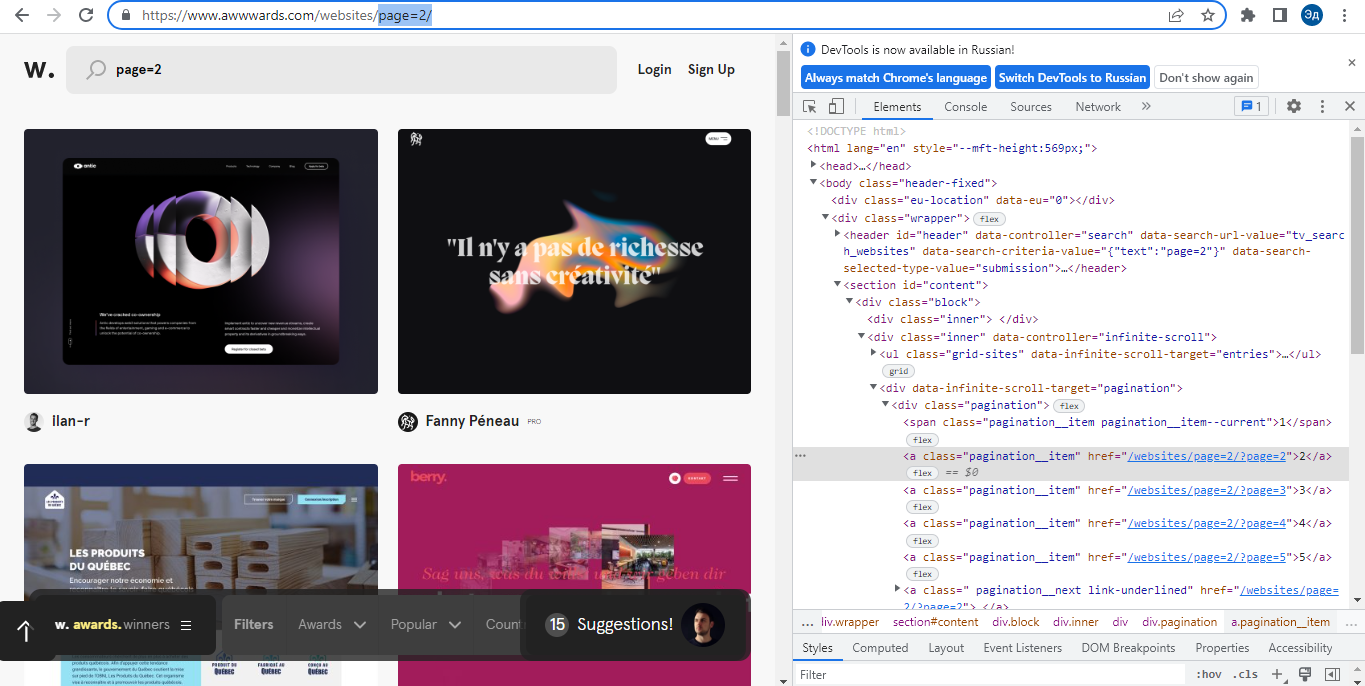
Карточки и панель навигации реализованы интересно. На первый взгляд может показаться, что здесь работает Java Script, который подгружает новые карточки, когда доходит до конца страницы. Однако, если мы посмотрим на DOM страницы, то поймем, что Java Script загружается не на сами карточки, а на отдельные страницы, которые содержат карточки сайта. То есть мы можем получить доступ к этим картам напрямую через URL страницы, на которой они расположены.
Лучшим способом сбора информации в этом случае будет обход каждой интересующей нас страницы и получение нужных данных из DOM этой страницы. После получения необходимой информации нам остается только записать ее в txt файл. Также можно было бы с помощью инструмента Selenium нажать на какой-нибудь нижний элемент страницы, чтобы прокрутить сайт и получить новую порцию карточек. Однако инструмент Selenium работает дольше обычных Get-запросов и требует больше вычислительных ресурсов, что делает его неэффективным при решении этой задачи.
Цель
Заказчик хотел собрать данные о сайтах онлайн-галереи Awwwards. Нужно было собрать все адреса сайтов из каталога онлайн галереи и записать их в txt файл
Решение
Парсинг любого сайта начинается с анализа и планирования работы. Первый шаг — просмотреть сайт, чтобы понять, с чем нам приходится иметь дело.
Сайт имеет стандартную структуру карточек сайтов, панель фильтрации поиска и панель навигации по страницам. Нас интересуют карточки сайтов и панель навигации по страницам, так как нам не нужны никакие критерии фильтрации.
Карточки и панель навигации реализованы интересно. На первый взгляд может показаться, что здесь работает Java Script, который подгружает новые карточки, когда доходит до конца страницы. Однако, если мы посмотрим на DOM страницы, то поймем, что Java Script загружается не на сами карточки, а на отдельные страницы, которые содержат карточки сайта. То есть мы можем получить доступ к этим картам напрямую через URL страницы, на которой они расположены.
Лучшим способом сбора информации в этом случае будет обход каждой интересующей нас страницы и получение нужных данных из DOM этой страницы. После получения необходимой информации нам остается только записать ее в txt файл. Также можно было бы с помощью инструмента Selenium нажать на какой-нибудь нижний элемент страницы, чтобы прокрутить сайт и получить новую порцию карточек. Однако инструмент Selenium работает дольше обычных Get-запросов и требует больше вычислительных ресурсов, что делает его неэффективным при решении этой задачи.